一、自动驾驶发展逐步从技术驱动转向数据驱动
如今,自动驾驶传感器方案及计算平台已日趋同质化,供应商技术差距日益收窄。近两年自动驾驶技术迭代飞速推进,量产落地加速。根据佐思数据中心,2021 年,国内L2级辅助驾驶乘用车上险量累计达479.0万辆,同比增长 58.0%。2022 年 1-6 月,中国L2级辅助驾驶在乘用车新车市场渗透率攀升至32.4%。
对于自动驾驶而言,数据贯穿研发、测试、量产、运营维护等全生命周期。伴随智能网联汽车传感器数量的快速增加,ADAS和自动驾驶车辆数据的生成量也呈现指数级增长,从GB到TB、PB、EB直至将来的ZB。以数据驱动的汽车进化,满足用户个性化的需求,车企才能走实走远。
根据《汽车采集数据处理安全指南》,汽车采集数据是指汽车传感设备、控制单元采集的数据,以及对其进行加工后产生的数据,可细分为车外数据、座舱数据、运行数据和位置轨迹数据等。
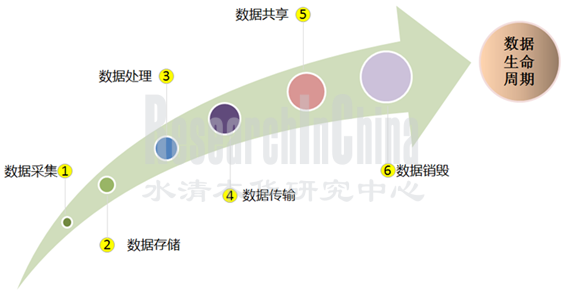
根据网信办2021年8月颁布的《汽车数据安全管理若干规定(试行)》对汽车数据收集、分析、存储、传输、查询、应用、删除等全流程做了详细的规定。在开展汽车数据处理过程中坚持“车内处理”、“默认不收集”、“精度范围适用”、“脱敏处理”等数据处理原则,减少对汽车数据的无序收集和违规滥用。在自动驾驶技术开发过程中,数据收集及处理等首先要合法合规。
数据采集/清洗
从汽车摄像头、毫米波雷达、激光雷达及超声波雷达收集来的大量非结构化数据(图像、视频、语音)可能是原始的和混乱的。为使数据有意义,需对其进行清理、结构化与整理。首先将来自多个来源的数据导入适当的存储库,标准化数据格式,并根据相关规则进行聚合。而后检查损坏、重复或丢失的数据点,并丢弃可能影响数据集整体质量的不需要的数据。最后,用标签对在不同条件下捕获的视频进行分类,例如白天、夜晚、晴天、下雨等。此步骤提供了对将用于训练、验证的清洗后的结构化数据。
数据标注
对数据采集后经过清洗的结构化数据需要进行标注。标注是将编码值分配给原始数据的过程。编码值包括但不限于分配类标签、绘制边界框和标记对象边界。需要高质量的标注来教授监督学习模型对象是什么以及测量训练模型的性能。
在自动驾驶领域,数据标注处理的场景通常包括换道超车、通过路口、无红绿灯控制的无保护左转、右转,以及一些复杂的长尾场景诸如闯红灯车辆、横穿马路的行人、路边违章停靠的车辆等。
常用的标注工具包括图片通用拉框、车道线标注、驾驶员面部标注、3D点云标注、2D/3D融合标注、全景语义分割等。由于大数据的发展和大型数据集数量的增加,数据标注工具的使用不断迅速扩大。
数据传输
如今,数据采集的频率已进入毫秒级别,需要的是数千个信号维度(如总线信号、传感器内部状态、软件埋点、用户行为及环境感知数据等)的高精度数据,同时避免数据丢失、乱序、跳变及延时,并在高精度高质量前提下,极大压缩传输/存储成本。车联网数据的上下行链路比较长(从车端MCU、DCU、网关、4G/5G到云端)需要保证各链路节点的数据传输质量。
针对数据传输的新变化,部分企业已能提供高效的数据采集及车云一体传输方案,例如智协慧同EXCEEDDATA灵活数采平台方案,在车端边缘计算环境基于实时数据,实现了10毫秒级实时运算,用于触发灵活数据采集上传功能,上传的数据已经经过计算和筛选,显著降低上传的数据量。此外对车端原始信号进行100-300倍无损压缩和存储,云端管理平台保存无损高压缩比的车端高质量信号, 支持数采算法的下发、多种采集模式的触发、采集数据实时上传到业务桌面的一键式下载,按车辆、按事件、按时间段等多重灵活筛选,随用随解,存算分离,实现了车云同构的数据采集-计算-上传-加工的闭环;2021年,国内首个搭载智协慧同EXCEEDDATA解决方案的量产车型已落地(高合HiPhiX)。
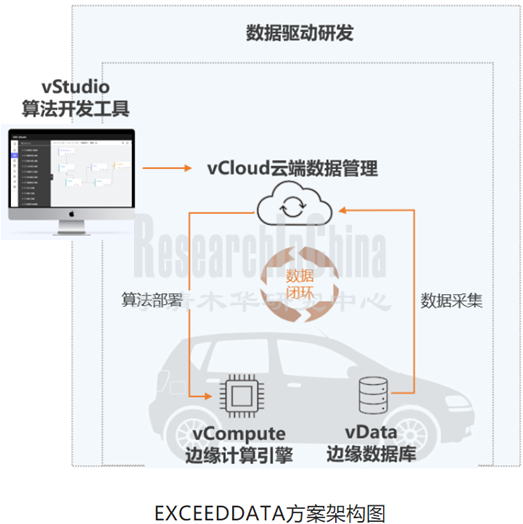
来源:智协慧同
数据存储
为更清晰感知周围环境,自动驾驶汽车增配更多传感器,并生成大量数据。一些高等级自动驾驶系统甚至配置40多个各类传感器,对车辆周边360°环境准确感知。自动驾驶系统的研发需经过数据采集、数据汇聚、清洗标记、模型训练、模拟仿真、大数据分析等多个环节,期间涉及对海量数据的汇聚存储,不同环节不同系统之间的数据流转,以及模型训练时对海量数据的读写。数据面临存储瓶颈的新挑战。
为此,众多云服务提供商在这方面的技术和能力成为了帮助车企制胜的关键。比如亚马逊云科技AWS以自动驾驶数据湖为中心,助力车企构建起端到端的自动驾驶数据闭环。借助Amazon Simple Storage Service (Amazon S3, 云上对象存储服务)构建自动驾驶数据湖,实现数据采集、数据管理和分析、数据标注、模型和算法开发、仿真验证、地图开发以及DevOps和MLOps,车企能更加容易地实现自动驾驶全流程的开发、测试和应用。
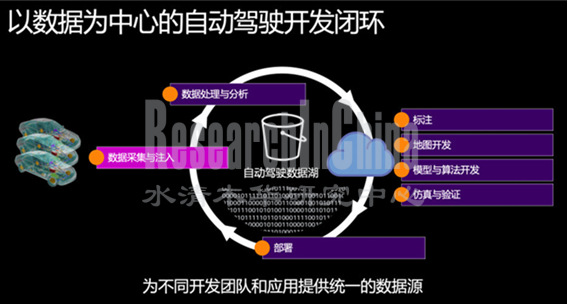
来源: AWS
在国内的科技巨头中,以百度数据闭环解决方案为例,其数据存储提供路侧及车辆多源数据信息的数据检索服务,用于业务平台的海量数据查找,具备多维度检索(车辆信息、里程数、自动驾驶时长等)、数据生产到销毁的整个生命周期的管理、支持全景数据视图、数据溯源和数据开放共享等优势。
百度自动驾驶数据闭环解决方案架构

来源:百度
二、自动驾驶高效开发需构建数据闭环系统
自动驾驶发展从技术驱动转向了数据驱动,但是数据驱动的商业模式面临诸多困难。
海量数据处理难: 高等级自动驾驶测试车每天采集的数据量是TB级别的,开发团队需要PB级的存储空间,但这些数据中,可用于训练的价值数据约只占不到5%。且对车载摄像头、激光雷达、高精定位等传感器采集的数据还有严格的安全合规要求,无疑对海量数据的接入、存储、脱敏、处理等带来了极大的挑战。
数据标注成本高:数据标注占据了大量的人力和时间成本。随自动驾驶高阶能力的发展,场景复杂度持续提升,会出现更多的难例场景。而提升车辆感知模型的精度,则对训练数据集的规模和质量提出了更高要求。传统人工标注在效率和成本方面,已难以满足模型训练对海量数据集的需求。
仿真测试效率低:虚拟仿真是加速自动驾驶算法训练的有效手段,但仿真场景构建难、还原度低,尤其是一些复杂、危险场景,很难构建。加之并行仿真能力不足,仿真测试的效率低,算法的迭代周期过长。
高精地图覆盖少:高精地图主要还是靠自采集、自制图,仅满足试验阶段指定道路的场景。后续要走向商用,扩展到全国各大城市的城区街道,在覆盖、动态更新,以及成本和效率方面都面临着非常突出的挑战。
为了解决各种困难和问题,自动驾驶高效开发需构建高效的数据闭环系统。
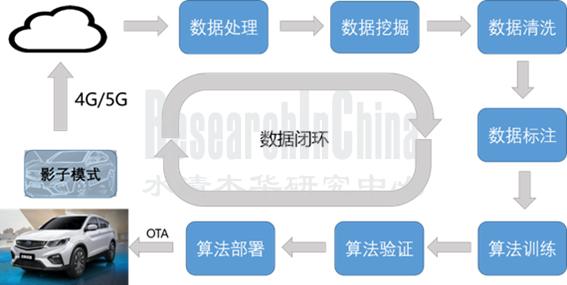
来源:福瑞泰克
就自动驾驶数据闭环而言,在自动驾驶落地过程中需要不断解决Corner Cases,为此必须拥有足够多的数据样本以及便捷的车端验证方式。影子模式就是解决Corner Cases的最佳解决方案之一。
影子模式由特斯拉2019年4月提出并应用到车端,进行相关决策的对比和触发数据上传。利用售出车辆上的自动驾驶软件持续记录传感器探测的数据,在适当时间选择性回传用于机器学习、改进原来的自动驾驶算法。

Dojo超级计算机能利用海量视频数据,做无人监管标注和训练。
2021年特斯拉全球交付93.62万辆汽车,其中中国工厂交付了48.41万辆。2022年上半年交付56万辆。特斯拉利用量产优势,通过影子模式不断优化算法。利用影子模式,通过百万已售车辆做测试车辆,对周围感知以及特殊路况进行捕捉,不断强化对于不确定性事件的预测和规避、学习能力。因为有百万量级的已售车辆支撑,覆盖的Corner Cases及极端工况就会更全面,灵活触发式采集的高质量数据能迭代出更优质的算法,而算法迭代的卓越度又决定着软件的价值。从软件升级订阅服务来讲,数据闭环的爆发力才刚刚崭露头角。
三、数据闭环成为自动驾驶迭代升级的核心
自动驾驶系统不断迭代的前提是算法的持续优化,而算法的卓越度又取决于数据闭环系统的效能,数据在自动驾驶开发每个场景的高效能流转至关重要,数据智能化将成为加速自动驾驶量产的关键。
2021年12月毫末智行正式发布了国内首个自动驾驶数据智能体系MANA雪湖,从感知、认知、标注、仿真、计算五大能力方面加速自动驾驶技术的演进。未来三年毫末辅助驾驶系统可搭载超100万台乘用车。毫末智行依靠其全自研的自动驾驶系统,在数据的积累、处理、应用上取得了显著优势。海量数据带来技术迭代优势。降本增效优势明显。
再比如,Momenta实现了领先的全流程数据驱动的技术能力,包括感知、融合、预测和规控等算法模块都可以通过数据驱动的方式高效的迭代与更新。其闭环自动化 (Closed Loop Automation)是一整套让数据流推动数据驱动的算法自动迭代的工具链。CLA能自动筛选出海量黄金数据,驱动算法的自动迭代,让自动驾驶飞轮越转越快。
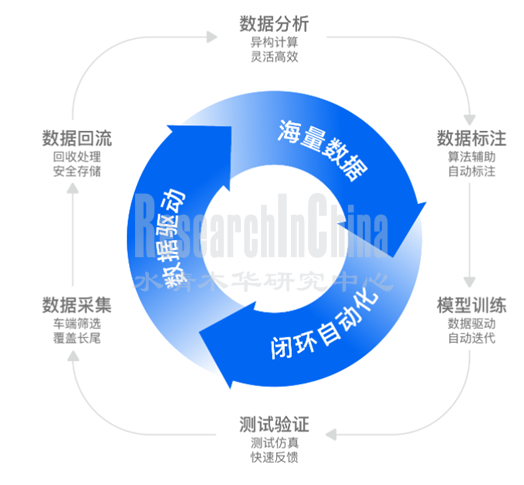
来源:Momenta
软件定义汽车背景下,数据、算法和算力是自动驾驶开发的三驾马车。车企研发周期缩短、功能迭代加速,未来能够持续地低成本、高效率、高效能收集数据,并通过真实数据迭代算法,最终形成数据闭环及商业闭环是自动驾驶企业可持续发展的关键所在。
第一章 自动驾驶数据产业链简介
1.1 汽车数据和自动驾驶数据概述
1.1.1 汽车数据分类
1.1.2 中国汽车数据安全相关法律法规
1.1.3 自动驾驶各级别对应数据量及算力需求
1.1.4 部分上市新车辅助驾驶算力情况
1.1.5 自动驾驶车辆数据存储基础要求
1.1.6 自动驾驶高效开发需构建数据闭环系统
1.1.7 传统数据闭环工作流程
1.1.8 AI数据闭环工作流程
1.2 数据采集
1.2.1 数据采集现状
1.2.2 数据采集的价值
1.2.3 传统结构化数据获取方式
1.2.4 非结构化数据
1.2.5 Corner Cases场景数据采集痛点
1.3 数据标注
1.3.1 数据标注定义
1.3.2 数据标注产业链与生态
1.3.3 自动驾驶数据标注
1.3.4 自动驾驶数据标注类型
1.3.5 模型训练所需的数据量更多
1.3.6 3D标注难度加大,门槛提高
1.3.7 L3+级别要求海量且更高质量的数据
1.4 影子模式
1.4.1 影子模式定义
1.4.2 特斯拉Autopilot的积累里程数
1.4.3 部分企业影子模式的应用例子
1.5 自动驾驶数据产业链概览
第二章 数据采集和标注代表厂商研究
2.1 云测数据
2.1.1 云测数据 公司简介
2.1.2 云测数据 智能驾驶解决方案
2.1.3 云测数据 数据采集与标注服务
2.1.4 云测数据 存储构架与数据可视化
2.1.5 云测数据 客户
2.2 曼孚科技
2.2.1 曼孚科技 公司简介
2.2.2 MindFlow SEED数据服务平台
2.2.3 曼孚科技 数据标注解决方案
2.2.4 曼孚科技 自动驾驶数据中台
2.3 澳鹏Appen
2.3.1 澳鹏Appen 公司简介
2.3.2 澳鹏数据标注平台
2.3.3 澳鹏数据标注工具集
2.3.4 澳鹏数据质量控制
2.3.5 澳鹏数据/平台服务部署
2.4 格物钛
2.4.1 格物钛 公司简介
2.4.2 格物钛 发展历程
2.4.3 格物钛 数据平台
2.4.4 格物钛 数据管理优势
2.4.5 格物钛 客户及合作伙伴
2.5 景联文科技
2.5.1 景联文 公司简介
2.5.2 景联文 智能驾驶数据解决方案
2.5.3 景联文 数采标注解决方案流程
2.6 海天瑞声
2.6.1 智能驾驶数据解决方案
2.6.2 自动驾驶相关数据标注技术
2.6.3 业绩情况
第三章 数据闭环方案提供商
3.1 昆易电子
3.1.1 昆易电子公司简介
3.1.2 昆易电子大事记
3.1.3 高阶自动驾驶数据采集方案介绍
3.1.4 高阶自动驾驶数据旁路采集方案
3.1.5 高阶自动驾驶数据真值采集方案
3.1.6 不同类型传感器的采集方案
3.1.7 不同类型传感器的旁路方案
3.1.8 数采方案产品介绍
3.1.9 昆易电子自动驾驶数据设备
3.1.10 昆易电子数采方案云端平台
3.1.11 昆易电子数据可视化与分析软件
3.1.12 昆易电子数采方案中数据同步精度
3.1.13 昆易电子数据回注设备:用于Corner Case复现
3.1.14 昆易电子数据回注设备:用于集群化回归测试
3.1.15 昆易电子数据回注设备:用于仿真闭环测试
3.1.16 昆易电子智驾回注整体介绍
3.1.17 昆易电子智驾回注功能-视频注入
3.2 智协慧同
3.2.1 智协慧同 公司简介
3.2.2 智协慧同赋能智能汽车全生命周期业务
3.2.3 智协慧同 车云计算产品组成
3.2.4 智协慧同 车云计算解决方案
3.2.5 智协慧同 数据闭环解决方案
3.2.6 智协慧同 结构化和非结构化数据融合采集
3.2.7 智协慧同 数采方案
3.2.8 EXD量产智驾灵活数据采集方案
3.2.9 EXD自动驾驶数采灵活触发场景
3.2.10 智协慧同 跨域多场景解决方案
3.2.11 EXD数据分析平台整体方案架构
3.2.12 智协慧同 车企客户与生态合作
3.3 百度数据闭环
3.3.1 百度自动驾驶的产品平台和数据平台
3.3.2 百度数据闭环解决方案架构
3.3.3 百度数据闭环解决方案-数据采集
3.3.4 百度数据闭环解决方案-数据处理
3.3.5 百度数据闭环解决方案-数据上传
3.3.6 百度数据闭环解决方案-数据存储
3.3.7 百度数据采集标注解决方案
3.3.8 百度自动驾驶:云仿真测试解决方案
3.3.9 百度云仿真测试解决方案优势
3.3.10 百度云仿真测试解决方案--人工设计仿真
3.3.11 百度云仿真测试解决方案—其他
3.3.12 百度自动驾驶仿真工具链—量产合作
3.4 世纪互联
3.4.1 世纪互联 公司简介
3.4.2 世纪互联 发展历程
3.4.3 世纪互联 数据中心全国资源分布
3.4.4 世纪互联自动驾驶解决方案
3.4.5 自动驾驶解决方案:采集(1)
3.4.6 自动驾驶解决方案:采集(2)
3.4.7 自动驾驶解决方案:标注
3.4.8 自动驾驶解决方案:训练/仿真
3.4.9 世纪互联 业绩情况
3.4.10 世纪互联 客户
3.5 Momenta
3.5.1 Momenta 公司简介
3.5.2 Momenta 三阶段建设
3.5.3 Momenta 数据闭环自动化
3.5.4 Momenta 核心技术
3.5.5 Momenta 自动驾驶解决方案
3.5.6 Momenta 数据闭环应用案例
3.6 天瞳威视
3.6.1 天瞳威视 公司简介
3.6.2 天瞳威视 数据采集
3.6.3 天瞳威视 AV数据记录系统
3.6.4 天瞳威视 自研工具链
3.7 整数智能
3.7.1 整数智能 公司简介
3.7.2 整数智能 新版数据标注平台
3.7.3 整数智能 标准化数据生产流程
3.8 杉岩数据
3.8.1 杉岩数据 公司简介
3.8.2 杉岩数据 存储方案
3.9 Amazon
3.9.1 AWS汽车行业解决方案
3.9.2 Amazon SageMaker
3.9.3 Amazon SageMaker特点
3.9.4 Amazon SageMaker数据标注
3.9.5 Amazon EMR大数据云平台
第四章 主要Tier1/Tier2的数据闭环布局
4.1 宏景智驾
4.1.1 宏景智驾 公司简介
4.1.2 宏景智驾 数据云平台
4.2 小马智行
4.2.1 小马智行 公司简介
4.2.2 小马智行 自动驾驶基础架构平台
4.2.3 小马智行 全栈自研数据闭环工具链特点
4.3 福瑞泰克
4.3.1 福瑞泰克 公司简介
4.3.2 福瑞泰克 端到端全栈流程
4.3.3 福瑞泰克 数据闭环解决方案
4.4 四维图新
4.4.1 四维图新 公司简介
4.4.2 四维图新“芯片+数据+算法闭环打造高精度地图”
4.5 智行者
4.5.1 智行者 公司简介
4.5.2 智行者 发展历程及融资情况
4.5.3 数据驱动的自动驾驶量产解决方案
4.5.4 智行者 AVDC数据闭环系统
4.6 知行科技
4.6.1 知行科技 公司简介
4.6.2 知行科技 全场景算法能力
4.6.3 知行科技 大数据闭环系统
4.7 毫末智行
4.7.1 毫末智行MANA
4.7.2 毫末智行MANA特点
4.7.3 毫末智行建成数据闭环
4.8 驭势科技
4.8.1 驭势科技的U-Drive智能驾驶系统
4.8.2 驭势科技 云端运营管理平台
4.8.3 驭势科技的影子模式
4.9 其他Tier1/Tier2
4.9.1 MINIEYE
4.9.2 中海庭
4.9.3 领骏科技
4.9.4 禾多科技
4.9.5 均胜智能
4.9.6 东软睿驰
4.9.7 蘑菇车联
4.9.8 觉非科技
4.9.9 轻舟智航
4.9.10 AutoX
第五章 其他企业的数据闭环布局
5.1 芯片厂家的数据闭环布局
5.1.1 地平线的数据闭环开发平台
5.1.2 黑芝麻智能数据闭环解决方案
5.1.3 英伟达机器学习平台MAGLEV
5.2 特斯拉的数据闭环布局
5.2.1 特斯拉Autopilot模型迭代的数据引擎体系
5.2.2 特斯拉数据引擎
5.2.3 特斯拉超级计算机Dojo
5.3 DeepWay
5.3.1 DeepWay数据闭环总体路线
5.3.2 DeepWay数据与场景库
5.3.3 DeepWay算法训练与仿真