2025年,推理技术的重点会向多模态推理转移,常用的训练技术包括指令微调、多模态上下文学习与多模态思维链(M - CoT)等,多通过多模态融合对齐技术与LLM的推理技术结合而成。
部分多模态推理技术
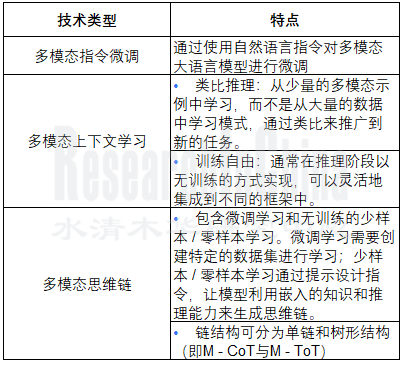
整理:佐思汽研
可解释性成为AI与用户的信任桥梁
在用户体会到AI的“好用”之前,首先需要满足用户对AI的“信任”,所以,2025年,AI系统运行的可解释性成为汽车AI用户基数增长的关键一环,该痛点也可通过长思维链的展示来解决。
AI系统的可解释性可通过数据可解释性、模型可解释性和事后可解释性三个层面分别实现:
AI可解释性的三个层面
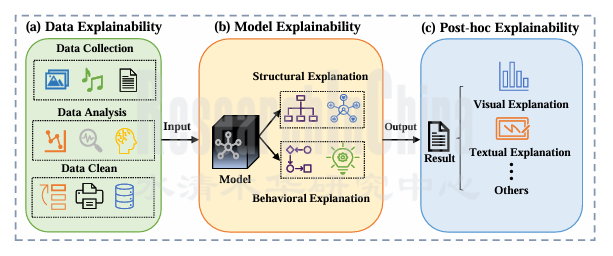
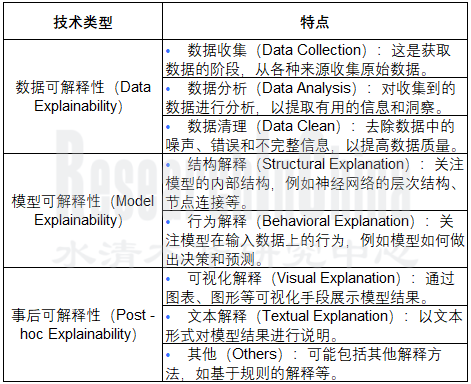
来源:IEEE;整理:佐思汽研
以理想为例,理想 L3 智驾通过 “AI 推理可视化技术”,可直观呈现端到端 + VLM 模型的思考过程,涵盖从物理世界感知输入到大模型完成行驶决策输出的全流程,提升用户对智能驾驶系统的信任。
理想L3智驾的可解释性

来源:理想
理想的“AI推理可视化技术”中:
• Attention(注意力系统)主要负责展示车辆感知到的交通和环境路况信息,能对实时视频流中的交通参与者进行行为评估,并使用热力图展示评估对象。
• E2E(端到端模型)用于展示行驶轨迹输出的思考过程。模型会思考不同的行驶轨迹,展示 10 个候选输出结果,最终采用概率最大的输出结果作为行驶路径。
• VLM(视觉语言模型)可展示自身的感知、推理和决策过程,其工作过程使用对话形式展示。
同时,理想Agent“理想同学”也提供可视化的工作流:
“理想同学”工作流
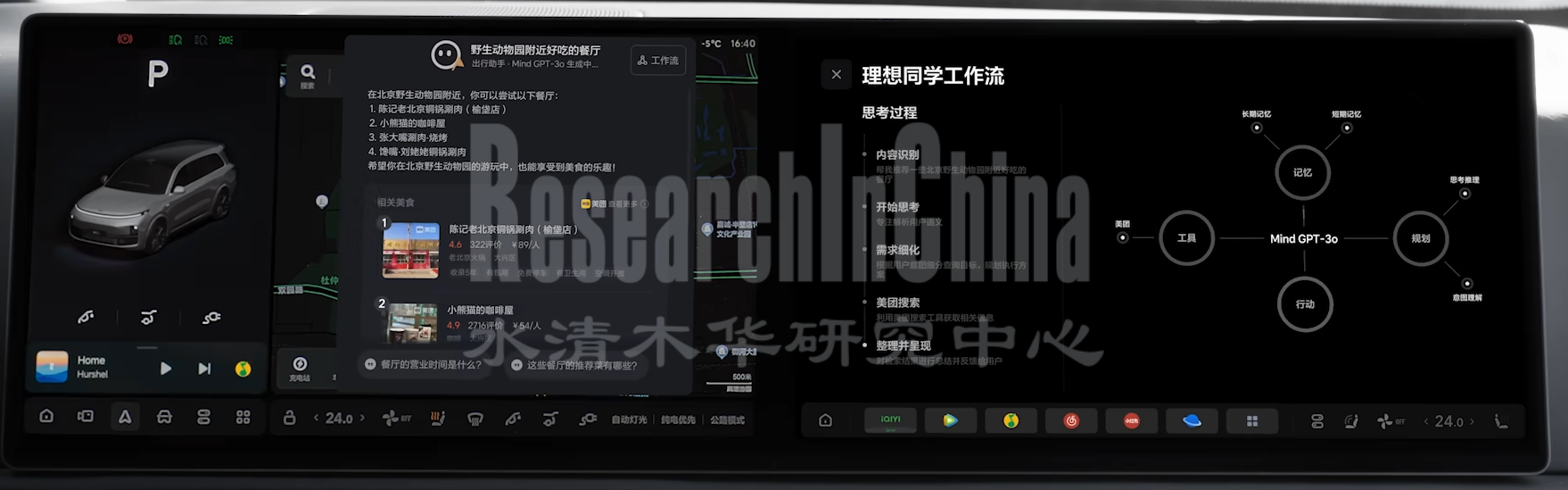
来源:理想
同样通过长思维链进行推理流程拆解的还有各个推理模型的对话界面,以DeepSeek R1为例,在与用户的对话中,会先通过思维链展示每一个节点的决策,并通过自然语言进行说明。
DeepSeek R1长思维链界面
来源:DeepSeek R1对话界面
此外,智谱的GLM-Zero-Preview、阿里的QwQ-32B-Preview、天工4.0 o1等大部分推理模型均支持长思维链推理流程展示。
DeepSeek降低大模型上车的门槛,性能提升与降本兼得
推理能力乃至综合性能的提升,是否意味着需要付出高额成本?从DeepSeek的爆火来看,并不是。2025年初,主机厂先后接入DeepSeek,从应用详情来看,基本上是以提升车载大模型的综合能力为主。
2025年初,部分主机厂与DeepSeek合作情况
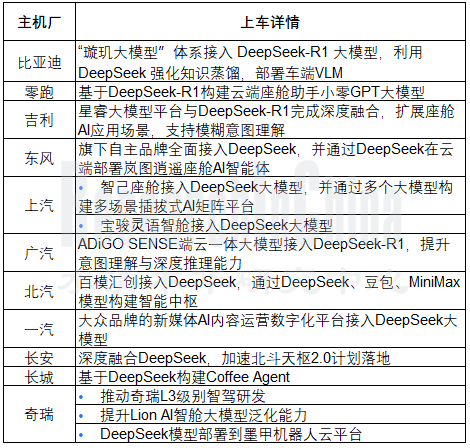
整理:佐思汽研
事实上,DeepSeek系列模型推出之前,各大主机厂已经按照自己的节奏有序推进旗下车载AI大模型的开发与迭代工作。以座舱助手为例,部分主机厂的方案已经初步完成构建,并已接入云端大模型供应商试运行或初步敲定供应商,其中不乏阿里云、腾讯云等云服务厂商以及智谱等大模型公司,2025年初再次接入DeepSeek,看重的包括:
• 强大的推理性能表现,如推理模型R1的性能与OPEN AI 推理模型o1相当,甚至在数学逻辑方面更为突出;
• 更低的成本,在保证性能的同时,训练与推理成本均保持在同行业较低水平。
DeepSeek R1与OPEN AI o1模型成本的比较
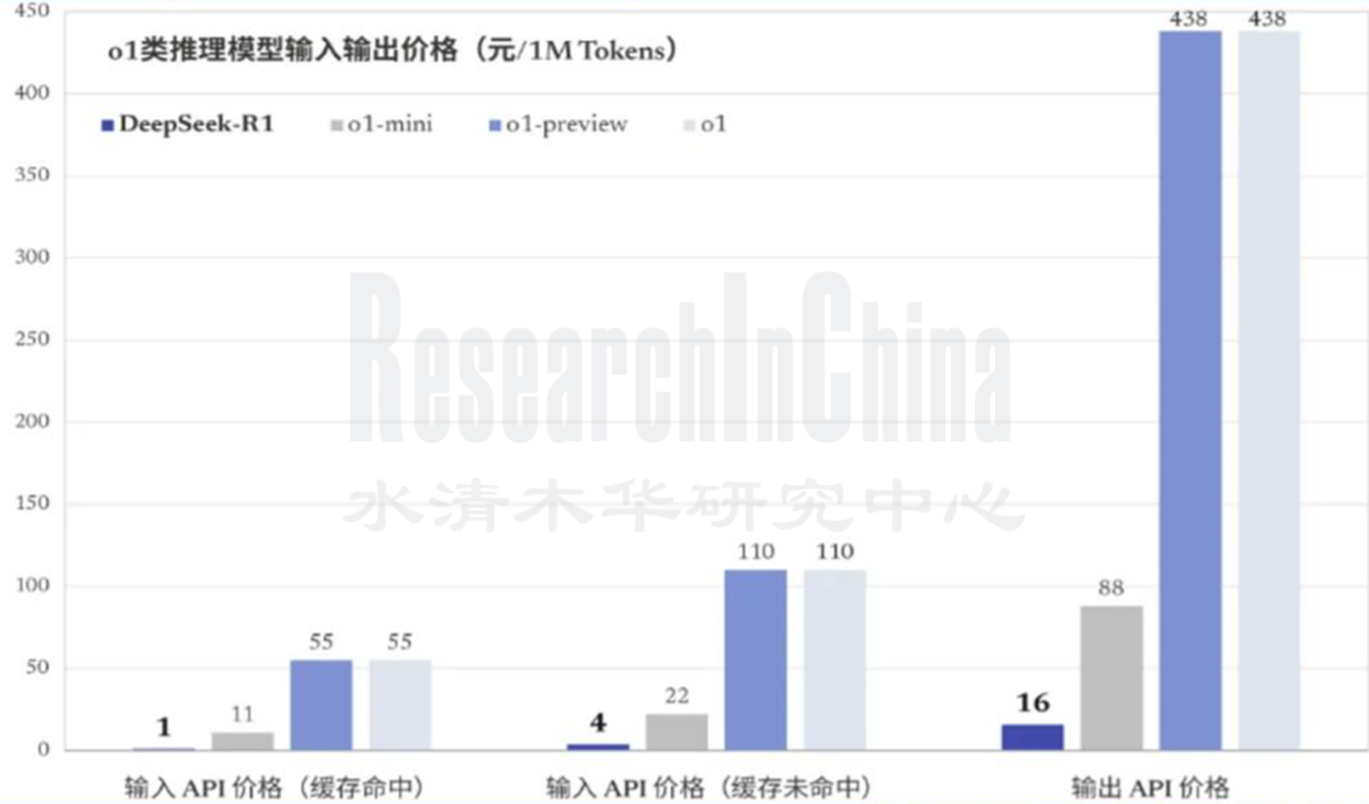
来源:公开信息
以上2点优势均在DeepSeek的技术创新上有所体现:
DeepSeek系列的部分技术对大模型性能和成本的影响
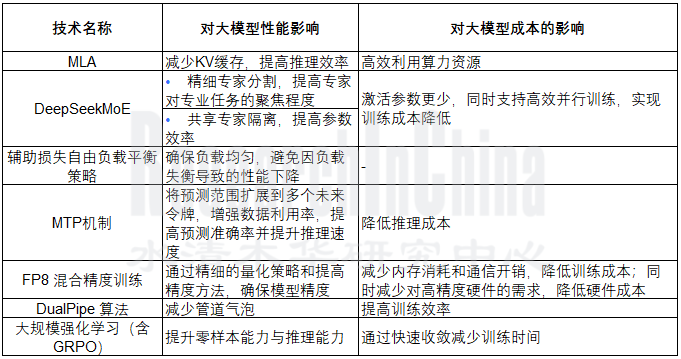
整理:佐思汽研
通过接入DeepSeek,主机厂在部署智驾和座舱助手时,可以切实地降低大模型性能硬件采购、模型训练与维护成本,同时保证性能不下降:
• 低计算开销技术推动高阶智驾、智舱平权,意味着低算力车载芯片(如边缘计算单元)上也可实现部署高性能模型,降低对高成本GPU的依赖;再结合DualPipe算法、FP8混合精度训练等技术,优化算力利用率,从而实现中低端车型也能部署高阶座舱功能、高阶智驾系统,加速智能座舱的普及。
• 实时性增强,在汽车行驶环境下,智驾系统需实时处理大量传感器数据,座舱助手需要快速响应用户指令,而车端计算资源有限。DeepSeek 计算开销的降低使传感器数据的处理速度更快,可更高效的利用智驾芯片算力(服务器端训练阶段,DeepSeek实现了对英伟达A100芯片90%的算力利用率),同时降低延迟(如在高通8650平台上,芯片算力同为100TOPS时,使用DeepSeek推理响应时间从20毫秒降至9 - 10毫秒)。在智驾系统中,可确保驾驶决策及时准确,提升驾驶安全性和用户体验。在座舱系统中,支持座舱助手快速响应用户语音指令,实现流畅人机交互。
吉利星睿大模型的系统2接入DeepSeek R1
