端到端智能驾驶的本质是借助大规模高质量人类驾驶数据实现驾驶行为的模仿。从技术路径看,基于模仿学习的模式虽可趋近人类驾驶水平,但难以突破人类能力的上限。另一方面,高质量场景数据的稀缺性与驾驶数据质量的不均衡性,使得端到端智能驾驶方案达到人类驾驶能力上限非常困难,而起步就是千万级 Clips 的高质量数据回流机制则形成了较高的规模门槛。
2025年初引发行业关注的 DeepSeek-R1 模型爆火后,其基于纯强化学习的创新技术路径展现出独特优势。该方案通过少量优质数据完成冷启动,借助多阶段强化学习训练机制,有效降低大模型训练对数据规模的依赖,使模型规模扩展的 "规模定律(Scaling laws)" 得以延续。同时,强化学习领域的技术创新成果,同样能够迁移应用至端到端智能驾驶领域,并在智能驾驶中实现更加精准的环境感知、路径规划和决策控制,为打造更大规模、更强能力的智能模型奠定基础。
尤为重要的是,强化学习框架擅长在交互环境中自主生成推理链,能够催生大模型的长思维链(CoT)能力,显著提升逻辑推理效能,甚至展现出超越人类思维局限的潜力。同时,端到端智驾模型通过与世界模型生成的仿真环境进行互动,可以使模型对真实世界的物理规则拥有更深的理解。这种基于强化学习的大模型技术路线,为端到端智能驾驶算法的研发提供了全新思路,有望突破传统模仿学习的限制。
一
端到端模型向VLA范式演进
端到端模型的核心特征是通过神经网络直接建立视觉输入到驾驶轨迹输出的映射关系。由于缺乏对物理世界运行规律的深入理解,端到端模型在视觉输入→驾驶行为输出的过程中无需显式的语义理解或逻辑推理,以至于其无法解析用户给出的口令、交通规则或者文本这些语义信息。同时,由于其缺乏3D空间的感知能力,导致端到端模型在长尾场景上的泛化性存在明显不足。
而 VLA 视觉-语言-动作模型则是在此基础上进行了关键改进,它融入了大语言模型 L,将原来单一的视觉动作映射系统升级为视觉、语言、动作相结合的多模态协同系统。大语言模型的加入,为智能驾驶系统注入了人类的常识和逻辑推理能力,使 VLA 模型不再局限于数据驱动的弱 AI 模式,实现了向具备认知智能的通才系统的跨越。
VLA模型框架
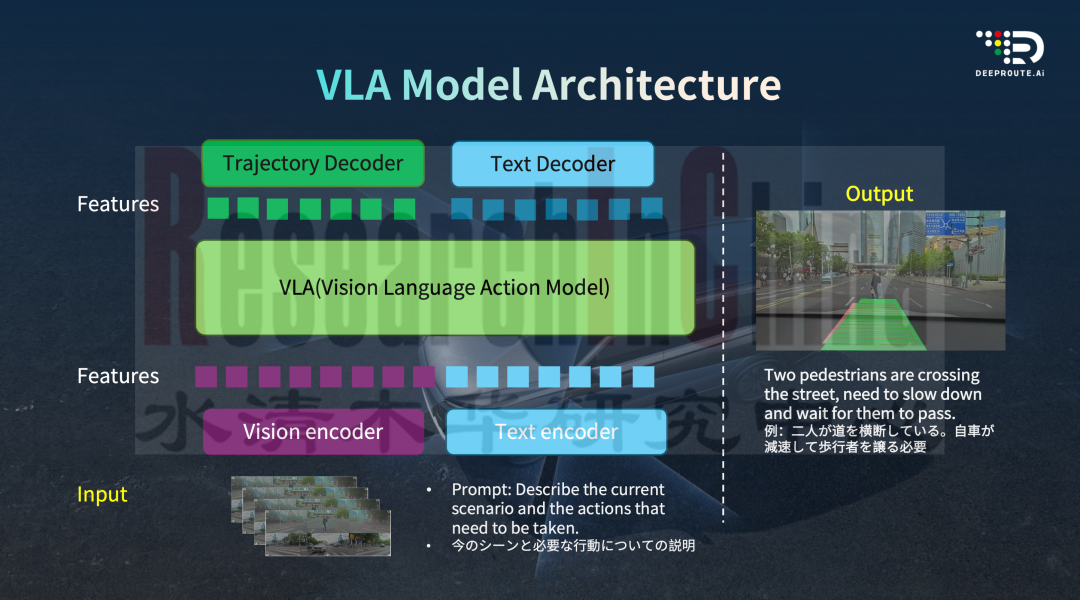
图片来源:元戎启行
•VLA的输入:来自摄像头、导航系统、地图等设备接收的「输入」信号。这些信号会分别通过两个编码器进行处理:视觉编码器(vision encoder)负责对图像数据进行编码,从中提取道路环境的高级特征;文本编码器(text encoder)则主要处理用户与车辆交互产生的文本信息,比如语音指令或设置参数。
•VLA的输出:轨迹解码器(trajectory decoder)会将模型生成的信息转化为具体的轨迹信号,明确告知车辆未来 10 秒到 30 秒的行驶计划,包括具体的速度控制和行驶路径。同时,文本解码器(text decoder)会同步生成自然语言解释,说明做出该动作的原因。例如当检测到有行人正在横穿马路时,系统不仅会规划减速停车的轨迹,还会生成 “前方有行人过街,需减速等待” 的文字说明,让用户清楚了解决策依据。
VLA的核心突破在于其“世界模型”构建能力和“思维链”的推理能力。VLA可以从传感器数据中提取丰富的环境信息,借助语言模型理解人类指令并生成可解释的决策过程,最后将多模态信息转化为具体的驾驶操作指令。当前大模型正在快速提升解释推理的能力。相比于之前的端到端方案,VLA可以更直观的解释为什么要这么做,可解释性将是VLA一大优势。同时,在大模型的加持下,智驾系统的视觉理解能力、空间理解能力都将一一突破。
到 2030 年,预计以视觉-语言-动作模型(VLA)为核心的端到端方案将占据 L3、L4 级智能驾驶市场超过一半的份额,这一技术变革正在重塑传统一级供应商(Tier1)的价值链地位。
理想汽车MindVLA进化路径
理想汽车今年融合了端到端(End-to-End, E2E)以及视觉语言模型(Visual Language Model, VLM)两种方案,发展到了更为先进的视觉-语言-行动(Vision-Language-Action, VLA)架构。主要因为去年的双系统架构存在明显的两个缺点:
•限制一:双系统架构采用单一处理流程,将相机、激光雷达、自车姿态和导航信息输入,通过3D编码器和动作解码器直接输出轨迹。同时端到端模型基于判别式AI而非生成式AI,不具备通识和常识推理能力,以至于只能应对已经学习过的场景,在长尾场景下的泛化能力不足。这种方法虽简洁,但在处理复杂空间理解和语言交互方面存在局限性。
•限制二:双系统架构在借助系统 2 对端到端系统 1 开展语义理解辅助工作时,暴露出技术层面的不足。当下视觉语言模型的输入数据源较为单一,主要依靠前置摄像头获取的 2D 平面数据,而车周摄像头与后视摄像头所提供的全方向环境视角信息并未被有效纳入。并且系统2在3D空间理解能力上存在明显短板,而这种能力恰恰是指导轨迹输出所必需的核心技术要素。
在VLA架构下,视觉空间智能(V-Spatial Intelligence)负责3D数据处理和空间理解,配备3D分词器;语言智能(L-Linguistic Intelligence)采用MindGPT大型语言模型融合空间标记并处理语义信息;行动策略(A-Action Policy)则通过集体行动生成器整合决策最终生成行动轨迹。MindVLA 架构强化了空间信息的 token 化处理(3D Tokenizer)、语言模型的场景理解(MindGPT)及集体行动的生成能力(Collective Action Generator),使得VLA在保持强大空间语言推理能力的同时,实现了视觉、语言、动作三个模态的特征在统一空间中的集体建模与对齐,有望解决未来复杂场景下的智能决策需求。
理想汽车MindVLA进化路径

图片来源:理想汽车
二
VLA模型的训练过程及强化学习的应用
在大型语言模型(LLM)的后训练(Post-traning)中,强化学习(RL)的应用愈发普遍。以年初备受瞩目的 DeepSeek-R1 为例,强化学习作为关键训练手段,通过设计恰当的奖励机制,有效激活了基础模型的推理能力。这种技术优势不仅在语言模型领域显现价值,也引起了智能驾驶行业的关注,目前已有多家厂商在自己的智驾技术中引入强化学习。
VLA模型的训练分为「基座模型的预训练」与「领域微调」两大阶段。预训练阶段通过海量数据赋予模型通用认知能力,如理解语境、逻辑推理等;而在智能驾驶领域的微调阶段,需通过监督学习建立基础驾驶规则(如车道保持、障碍物识别),再借助强化学习(RL)完成关键升级。强化学习借鉴了自然语言处理中的成功经验(如 RLHF 对齐人类偏好),在驾驶场景中通过「开环 + 闭环」机制优化决策:开环阶段利用历史接管数据校准安全逻辑,闭环阶段通过虚拟场景生成技术(如世界模型)模拟极端工况,让模型主动试错并迭代策略,突破传统端到端模型依赖海量标注数据的局限。
模仿学习(IL)
•模仿学习中的场景克隆策略(BC),核心是通过学习人类司机等专家的驾驶轨迹来制定策略。在智能驾驶领域,这种方法主要依靠分析大量驾驶数据,模仿人类的驾驶行为。它的优势在于实现简单且计算效率高,但缺陷也很明显 —— 难以应对未遇见过的特殊场景或异常情况。
•从训练机制来看,场景克隆策略采用开环方式,依赖分布规律的驾驶演示数据。但现实驾驶是典型的闭环过程,每一步操作的细微偏差都可能随时间累积,形成复合误差并引发未知场景。这导致通过场景克隆训练的策略,在陌生情境下往往表现不佳,其鲁棒性受到行业关注。
强化学习(RL)的原理是通过奖励函数优化动作策略:
•强化学习模型通过在模拟交通场景中不断交互,依靠奖励机制调整优化驾驶策略,这种方式能让模型在复杂动态的交通环境中学会更合理的决策。不过,强化学习在实际应用中存在明显不足:一方面训练效率不高,需要大量试错才能得到可用模型;另一方面无法直接在真实道路环境中训练 —— 毕竟真实驾驶场景承受不起频繁试错,成本太高。目前的仿真训练大多基于游戏引擎生成的传感器数据,而真实环境依赖物体本身的信息而非传感器输入,导致仿真结果与实际场景存在差距。
•还有一个问题是人类行为对齐难题:强化学习的探索过程可能让模型策略偏离人类驾驶习惯,出现动作不连贯的情况。为解决这一问题,现在通常在强化学习训练时引入模仿学习作为正则化项,通过融入人类驾驶数据,让模型策略保持与人类行为的相似性。
理想汽车MindVLA训练方法
第一阶段:理想汽车 VLA 模型的训练过程分为四个阶段:VL 视觉语言基座模型预训练、辅助驾驶后训练、辅助驾驶强化学习以及司机 Agent 构建。其中,VL 基座模型的预训练是整个训练体系的核心环节。在早期双系统阶段,理想曾采用阿里通义千问的 Qwen-VL 视觉语言模型,而在自研最新的 VL 基座模型时,通过部分集成 DeepSeek 语言模型能力,李想表示有效缩短了 9 个月的研发周期,节省了数亿元开发成本。
基于这一预训练形成的基座模型,理想进一步将其进行技术优化,通过模型蒸馏技术生成了一个参数量 36 亿的车端专用小模型,满足车载计算平台的部署需求。
理想汽车VL(视觉语言)基座预训练

图片来源:理想汽车
第二、三阶段:
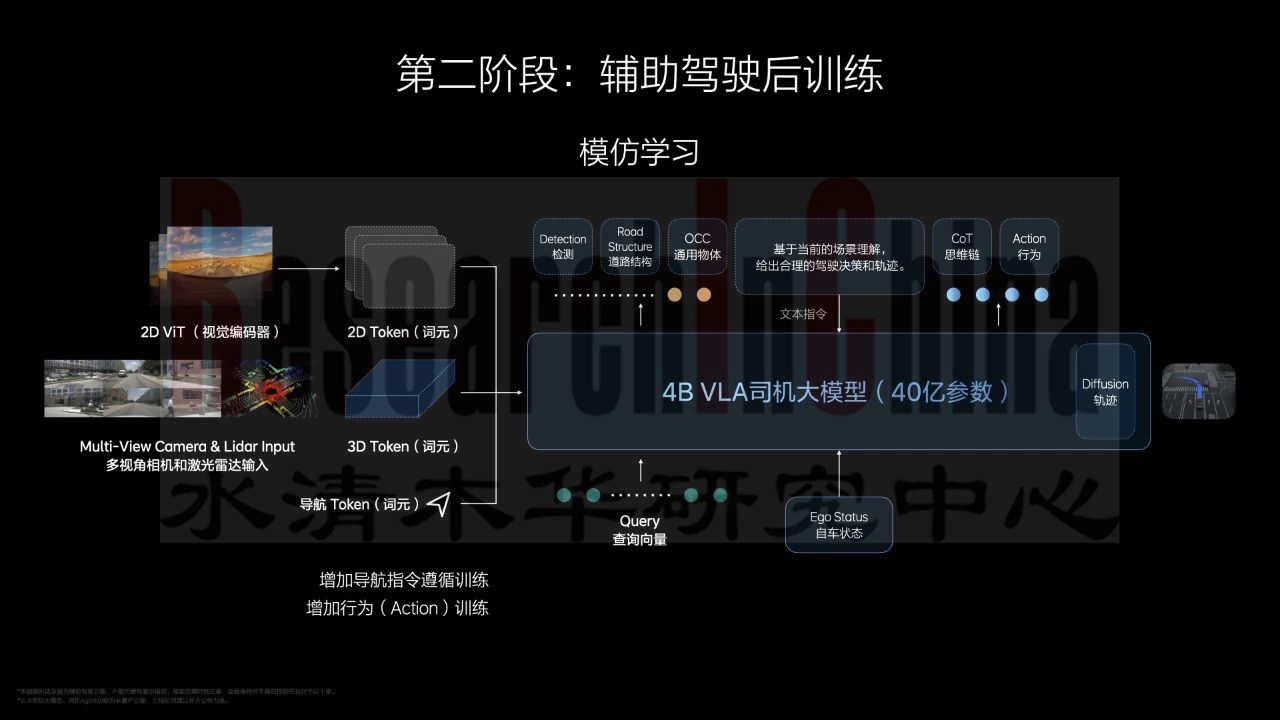
•云端训练完成的 VLA 模型,最终目标是在车端平台落地应用。由于车端算力与云端存在差异,需要通过剪枝、量化等模型压缩技术对云端模型进行蒸馏优化。理想汽车的具体做法是:在完成 320 亿参数的 VL 基座模型训练后,首先将其蒸馏为适配车端算力条件的 40 亿参数模型,在此基础上再开展强化学习训练,确保模型既能满足车载计算平台的运行要求,又能保持足够的决策能力。
•理想汽车 VLA 模型训练的第二、三阶段 —— 辅助驾驶后训练与强化学习,可看作是对基座模型在智能驾驶领域的微调。其中,后训练阶段采用传统端到端方案的开环模仿学习方式,而强化学习阶段则通过开环与闭环结合的模式,成为 VLA 模型训练的核心改进点。
具体来看:
•开环强化学习:利用RLHF基于人类反馈的强化学习机制,主要目标是让驾驶策略贴合人类驾驶习惯和安全标准。理想利用历史积累的人类接管车辆数据进行训练,使模型明确区分 “合理操作” 与 “危险行为”,完成基础驾驶逻辑的校准。
•闭环强化学习(RL):通过构建世界模型生成大量虚拟训练和仿真场景,对模型进行高强度迭代训练。这种方式打破了传统依赖真实路况数据的局限,大幅降低了实际路测的时间和成本,实现了训练效率的提升。
这两个阶段通过 “先对齐人类偏好,再通过虚拟场景深度优化” 的组合,完成了从基础模型到专用驾驶模型的关键过渡。
理想汽车辅助驾驶强化学习
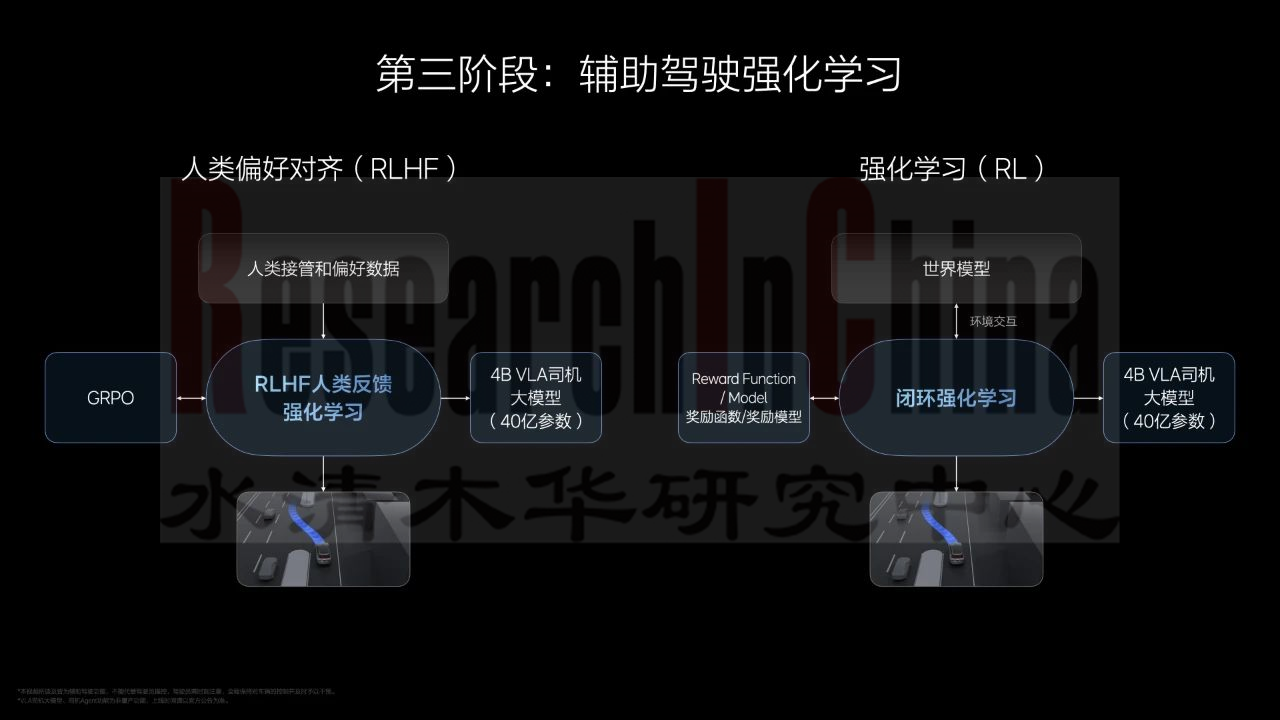
图片来源:理想汽车
三
世界模型与强化学习的协同应用
世界模型被视为端到端智能驾驶训练、评测和仿真的关键技术。其核心功能是根据传感器输入信号和车辆自身的运动状态,生成接近真实场景的模拟视频。这种能力让它能构建高度逼真的虚拟驾驶环境,使车辆的各种驾驶行为可以在安全可控的模拟场景中得到有效评估以及使智驾系统通过和模拟的真实世界交互的方式提升对真实世界物理法则及语义信息的理解。
强化学习训练:
•世界模型本质是基于神经网络的模型,能建立环境状态、动作选择和反馈奖励之间的关联模型,直接指导智能体的行为决策。在智能驾驶场景中,这套模型可根据实时环境状态生成最优行动策略。更关键的是,它能搭建接近真实动态的虚拟交互环境,为强化学习提供闭环训练平台 —— 系统在模拟环境中持续接收奖励反馈,不断优化策略。
•通过这种机制,端到端模型的两大核心能力有望显著提升:一是感知能力,对车辆、行人、障碍物等环境要素的识别精度和理解能力,二是预测能力,对其他交通参与者行为意图的预测准确性。这种从感知到决策的全链条优化,正是世界模型赋能智能驾驶的核心价值。
•华为近期发布的「乾崑智驾 ADS 4」也应用了世界模型技术。在其「世界引擎 + 世界行为模型(WEWA)」技术架构中,云端的「世界引擎」负责生成各类极端罕见的驾驶场景,并将这些场景转化为智驾系统的「训练考题」,如同模拟考试的「出题考官」。而车端的「世界行为模型」则具备全模态感知及多MoE专家决策能力,充当「实战教官」角色,让智驾系统在模拟环境中积累复杂场景的应对经验,实现从理论到实践的能力进阶。
•小鹏近期发布的云端世界基座模型以大语言模型为核心架构,通过海量优质多模态驾驶数据完成训练,具备视觉语义理解、逻辑链式推理和驾驶动作生成能力。目前团队正重点研发 720 亿参数规模的超大规模世界基座模型。该云端模型构建了从基座模型预训练、强化学习后训练,到模型蒸馏、车端模型预训练直至部署上车的全流程技术链路。整个体系采用强化学习与模型蒸馏相结合的技术路线,可高效产出体积小、智能化水平高的端侧部署模型。
理想汽车世界模型应用:
在智能驾驶领域,强化学习(RL)面临着因环境真实性不足而导致训练偏差的问题。MindVLA 依托自研的云端统一世界模型,该模型融合了重建与生成技术。其中,重建模型具备三维场景还原能力,生成模型则可实现新视角补全以及未见视角预测。通过将这两种技术路径相结合,MindVLA 构建出贴近真实世界、符合物理世界规律的仿真环境,为解决训练偏差问题提供了有效方案。
•该世界模型覆盖各类交通参与者与环境要素,构建起虚拟的真实交通世界。其采用自监督学习框架,基于多视角 RGB 图像实现动态 3D 场景重建,生成包含多尺度几何特征与语义信息的场景表示。场景以 3D 高斯点云形式建模,每个高斯点集成位置、颜色、透明度及协方差矩阵等参数,可高效渲染复杂交通环境中的光影与空间结构。
依托世界模型的强仿真能力,MindVLA 可在云端虚拟 3D 环境中开展数百万公里级驾驶模拟,替代部分实车路测,并低成本、准确地验证现实问题,显著提升了解决问题的效率,有效应对了模型黑盒带来的诸多挑战。通过在世界模型中进行海量的模拟测试和优化,VLA能够不断改进自身的决策和行为,并真正意义上的从“错误中学习”。确保在实际驾驶中的安全性和可靠性。
理想汽车世界模型架构
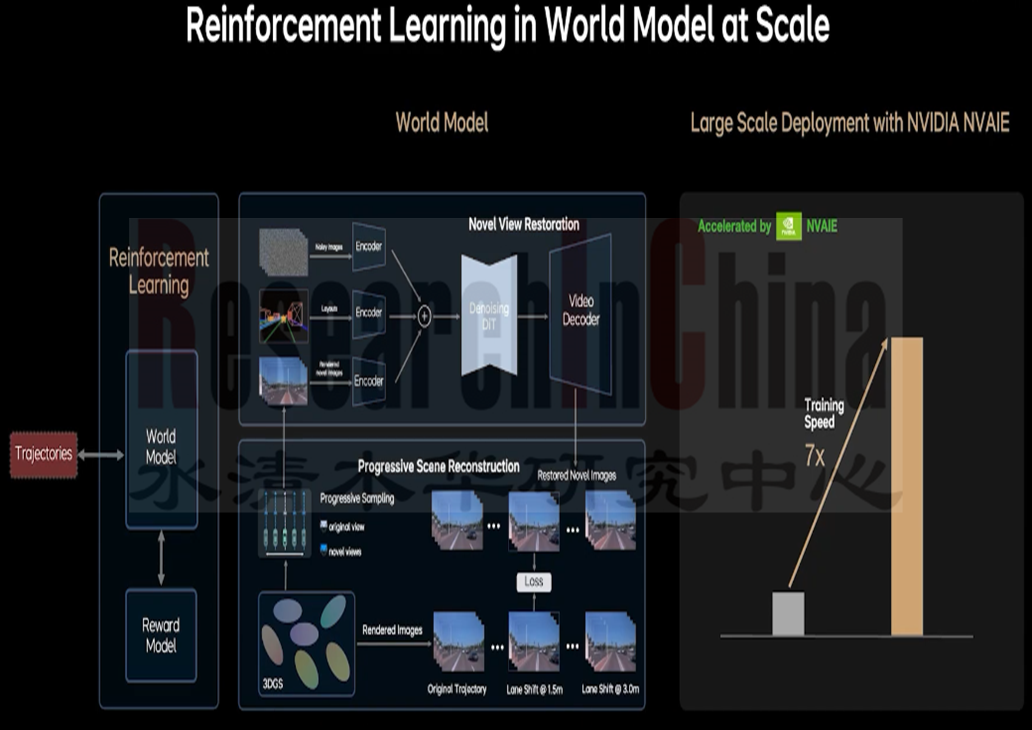
图片来源:理想汽车
01 端到端智能驾驶技术基础
1.1 端到端智能驾驶术语与概念
端到端智能驾驶术语解释
端到端智能驾驶术语解释
端到端相关概念的联系与区别
1.2 端到端智能驾驶介绍及发展现状
1.2.1 综述
端到端智能驾驶产生的背景
AI大模型对智能驾驶行业格局造成的影响推演
端到端智能驾驶产生的原因:商业价值
Transformer赋能智能驾驶
端到端与传统架构的区别(1)
端到端与传统架构的区别(2)
端到端架构演变
端到端智能驾驶演进路线
端到端智驾进展1
端到端智驾进展2
一段式端到端与两段式端到端的对比
主流一段式/分段式端到端系统性能参数对标
端到端智能驾驶引入多模态模型的意义
端到端规模化量产的痛点与解决方案(1)
端到端规模化量产的痛点与解决方案(2)
端到端系统的进展与挑战
端到端架构下的感知层
1.2.2 端到端模型实现方式
端到端的两种实现方法
端到端实现方法(1)
端到端实现方法(2)
主流强化学习算法
1.2.3 端到端模型验证方式
端到端智能驾驶数据集评测方式
端到端智能驾驶模型的三大仿真测试(1)
端到端智能驾驶模型的三大仿真测试(2)
端到端智能驾驶模型的三大仿真测试(3)
1.3 端到端智能驾驶经典案例分析
商汤UniAD
地平线VAD技术原理及架构
地平线VADv2技术原理及架构
VADv2的训练
DriveVLM技术原理及架构
理想汽车采用MoE
MOE和STR2
上海期智研究院E2E-AD模型SGADS
上交大E2E主动学习ActiveAD案例
端到端智能驾驶系统,大多数基于基石大模型开发
1.4 Foundation Models 基石大模型
1.4.1 基石大模型介绍
端到端系统的核心— Foundation Models 基石大模型
基石大模型之一LLM大语言模型:在智能驾驶应用举例
基石大模型之二Vision Foundation:在智能驾驶中的应用
基石大模型之二Vision Foundation(1)
基石大模型之二Vision Foundation(2)
基石大模型之二Vision Foundation(3)
基石大模型之三多模态基石大模型
1.4.2 基石大模型之多模态大模型
多模态大模型发展与简介
多模态大模型 VS 单模态大模型(1)
多模态大模型 VS 单模态大模型(2)
多模态大模型技术全景图
多模态信息表示
1.4.3 基石大模型之MLLM模型
多模态大语言模型(MLLM)
多模态大语言模型的架构及核心组件
多模态大语言模型—主流模型
多模态大语言模型在智能驾驶中的应用
Clip模型
LLaVA模型
1.5 VLM模型&VLA模型
VLM(Vision-Language Model)视觉语言模型应用
VLM(Vision-Language Model)视觉语言模型发展历史
VLM(Vision-Language Model)视觉语言模型架构
视觉语言模型(Vision-Language Model, VLM)在端到端智能驾驶中的应用原理
VLM(Vision-Language Model)在端到端智能驾驶中的应用
从VLM→VLA
VLA(Vision-Language-Action Model)模型
VLA(Vision-Language-Action Model)原理
VLA(Vision-Language-Action Model)模型的分类
EMMA 智能驾驶多模态模型核心功能
1.6 世界模型
世界模型关键定义及应用的发展
世界模型基本架构
世界模型框架设定及实施难点
基于Transformer和基于扩散模型的视频生成方法
WorldDreamer 技术原理及路径
世界模型或为实现端到端的理想方式之一
世界模型—虚拟训练数据的生成
世界模型—特斯拉 World Model
世界模型—英伟达
InfinityDrive
商汤绝影 InfinityDrive 参数表现
商汤绝影 InfinityDrive 流水线
商汤DiT架构及评价视频生成主要指标 FID/FV
1.7 端到端E2E-AD运动规划模型对比分析
智能驾驶端到端E2E-AD轨迹规划:几类产业界和学术界经典模型对比分析
Tesla:感知决策全栈一体化模型
Tesla:感知决策全栈一体化模型
Momenta端到端
Horizon Robotics 2023
DriveIRL
GenAD生成式E2E模型
1.8 VLA模型
VLA概念
端到端的核心之一大语言模型
VLA技术架构与关键技术
VLA的优势(1)
VLA的优势(2)
VLA的优势(3)
VLA模型部署的挑战(1)
VLA模型部署实时性以及内存占用挑战
VLA模型部署的挑战—数据(2)
VLA模型部署的挑战(3)
1.9 扩散模型
四种主流的生成模型
扩散模型原理
扩散模型优化智能驾驶轨迹生成核心环节
扩散模型优化智能驾驶轨迹生成
扩散模型在智能驾驶领域的应用
扩散模型实际应用案例
1.10 具身语言模型 ELM
具身语言大模型加快端到端方案落地
具身语言大模型加快端到端方案落地
具身语言大模型应用场景(1)
具身语言大模型应用场景(2)数据闭环
具身语言大模型应用场景(3)数据收集
具身语言大模型应用场景(4)定位/描述标注
具身语言大模型应用场景(5)Token选择
具身语言大模型应用场景(6)基准测试
具身语言大模型应用场景(7)实验结果
具身语言大模型应用场景(7)实验结果
具身语言大模型局限性与积极影响
02 端到端智能驾驶的技术路线和发展趋势
2.1 端到端智能驾驶的技术趋势
趋势一: 零样本学习
趋势二:基座模型
趋势三
趋势四
趋势五
趋势六
趋势七
趋势八
端到端趋势九
端到端趋势十
2.2 端到端智能驾驶的市场趋势
主流端到端系统厂商方案布局现状一览
ADAS Tier1 端到端系统厂商方案布局对比分析(1)
ADAS Tier1 端到端系统厂商方案布局对比分析(2)
ADAS Tier1 端到端系统厂商方案布局对比分析(3)
其他智能驾驶公司端到端系统厂商方案布局对比分析
主机厂端到端系统方案布局对比分析(1)
主机厂端到端系统方案布局对比分析(2)
主机厂端到端系统方案布局对比分析(3)
端到端系统赋能头部车企规模化落地无图城市NOA,实现全国都能开
国内主流主机厂各子品牌NOA与端到端落地进程表对比1:长安、长城、比亚迪
国内主流主机厂各子品牌NOA与端到端落地进程表对比2:一汽、广汽、吉利
国内主流主机厂各子品牌NOA与端到端落地进程表对比3:北汽、上汽、奇瑞、东风
国内主流主机厂各子品牌NOA与端到端落地进程表对比4:蔚来、小鹏、理想、小米、华为、零跑
2.3 端到端智能驾驶团队建设
端到端大模型对公司组织架构的影响(1)
端到端大模型对公司组织架构的影响(2)
国内主机厂及供应商端到端智能驾驶领军人物
国内主机厂端到端智能驾驶团队构建:小米
国内主机厂端到端智能驾驶团队构建:百度/理想
国内主机厂端到端智能驾驶团队构建:小米/百度
国内主机厂端到端智能驾驶团队构建:理想
国内主机厂端到端智能驾驶团队构建:理想
国内主机厂端到端智能驾驶团队构建:小鹏
国内主机厂端到端智能驾驶团队构建:比亚迪
国内主机厂端到端智能驾驶团队构建:蔚来
国内主机厂端到端智能驾驶团队构建:蔚来
国内供应商端到端智能驾驶团队构建:Momenta
国内供应商端到端智能驾驶团队构建:Momenta
国内供应商端到端智能驾驶团队构建:元戎启行
国内供应商端到端智能驾驶团队构建:元戎启行
国内主机厂端到端智能驾驶团队构建:华为
国内主机厂端到端智能驾驶团队构建:华为
国内供应商端到端智能驾驶团队构建:卓驭科技
国内供应商端到端智能驾驶团队构建:卓驭科技
国内供应商端到端智能驾驶团队构建:地平线
国内供应商端到端智能驾驶团队构建:地平线
03 端到端智能驾驶供应商研究
3.1 MOMENTA端到端
Momenta公司简介
2025年下半年将发布Momenta R6飞轮大模型
Momenta一段式端到端方案(1)
Momenta一段式端到端方案(2)
Momenta端到端规划架构
Momenta一段式端到端量产
Momenta高阶智驾量产客户与端到端量产客户
Momenta量产情况及合作客户
3.2 元戎启行端到端
元戎启行产品布局与战略部署
元戎启行端到端布局历程
元戎启行端到端方案与传统方案的区别
元戎启行端到端方案实施进度
元戎启行宣布与火山引擎达成深度合作
RoadAGI的实施平台
元戎启行VLA模型架构
元戎启行端到端VLA模型解析
元戎端到端定点量产项目及VLA模型特点
元戎启行端到端方案量产情况
元戎启行引入分层提示令牌
元戎启行端到端训练方案
元戎启行DINOv2在计算机视觉领域的应用价值
元戎启行智能驾驶VQA任务评价数据集
元戎启行评估翻译指标BLEU以及评估图像描述生成任务的自动评价指标CIDEr
元戎启行HoP与华为得分对比
3.3 华为端到端
华为端到端演进路线
华为ADS 4 全新WEWA 架构
华为ADS 4 和XMC深度融合及云端仿真验证
ADS 4:高速L3商用解决方案
华为端到端量产情况
华为车BU发展历程
华为ADS 2.0(1) 端到端理念与感知算法
华为ADS 2.0(2) 端到端理念与感知算法
华为ADS 2.0总结
华为ADS 3.0(1)
华为ADS 3.0(2):端到端
华为ADS 3.0(3):端到端
华为ADS 3.0(3):ASD3.0 VS. ASD2.0
ADS 3.0端到端方案落地案例(1)
ADS 3.0端到端方案落地案例(2)
ADS 3.0端到端方案落地案例(3)
华为多模态LLM端到端智能驾驶方案
端到端测试
华为DriveGPT4架构
华为端到端训练方案示例解析
华为DriveGPT4的训练分为两个阶段
华为DriveGPT4与GPT4V的对比
3.4 地平线端到端
地平线公司简介
地平线主要合作伙伴
地平线城区辅助驾驶系统HSD
地平线征程6系列芯片
UMGen
GoalFlow
MomAD
DiffusionDrive
RAD
地平线量产情况
地平线端到端Super Drive高阶智能驾驶及优势
地平线Super Drive 架构及技术原理
地平线智驾系统Senna(大模型+端到端)
地平线智驾系统Senna核心技术及训练方式
地平线智驾系统Senna核心模块
3.5 卓驭科技端到端
卓驭科技简介
卓驭科技研发与生产
卓驭成行智驾端到端算法演进路线
卓驭端到端世界模型架构
卓驭端到端世界模型双阶段训练模型
卓驭生成式智驾GenDrive核心功能
卓驭生成式智驾核心技术
卓驭端到量产情况
卓驭两段式端到端解析
卓驭一段式可解释端到端解析
卓驭科技端到端量产客户
3.6 英伟达端到端
英伟达简介
Hydra-MDP++
世界基础模型开发平台
Cosmos训练范式
英伟达智能驾驶解决方案
英伟达DRIVE Thor芯片
NVIDIA为智能驾驶打造的基础平台
NVIDIA Multicast 的核心设计思想
NVIDIA新一代车载计算平台
NVIDIA最新发布端到端智能驾驶框架Hydra-MDP
NVIDIA 自研搭建模型架构 Model room
智己汽车、NVIDIA与Momenta三方合作
NVIDIA最新发布端到端智能驾驶框架
3.7 Bosch端到端
博世纵横辅助驾驶方案
博世基于端到端模型的城区辅助驾驶方案
博世端到端量产情况
博世智驾中国战略布局(1)
基于端到端发展趋势,博世智驾启动新一轮组织架构变革和战略合作
在推出BEV+Transformer的高阶智能驾驶解决方案之后,博世加速端到端智驾布局
博世智能驾驶算法演进路线规划
3.8 百度端到端
百度DriVerse
百度Apollo简介
百度在智能驾驶领域的战略布局
百度两段式端到端
两段式端到端技术架构量产车型
百度汽车云3.0从三方面赋能端到端系统(1)
百度汽车云3.0从三方面赋能端到端系统(2)
3.9 商汤绝影端到端
商汤绝影公司简介
商汤绝影智驾端到端算法演进路线
商汤绝影R-UniAD架构
R-UniAD实际演示
商汤绝影开悟世界模型2.0
商汤绝影量产情况
商汤绝影发布UniAD端到端解决方案
DriveAGI:新一代智能驾驶大模型及其优势
DiFSD
DiFSD:技术解读
3.10 轻舟智航端到端
轻舟智航公司简介
轻舟智航「安全的端到端」架构
轻舟智航「安全的端到端」数据及模型训练闭环
轻舟乘风中高阶辅助驾驶解决方案
轻舟智航端到端量产情况
“轻舟乘风”高阶智驾解决方案(1)
“轻舟乘风”高阶智驾解决方案(2)
轻舟智航端到端布局
轻舟智航端到端布局优势
3.11 Wayve端到端
Wayve 公司简介
Wayve 智能驾驶 AV 2.0优势
Wayve最新进展:世界模型GAIA-1体系结构
Wayve世界模型GAIA-1
Wayve世界模型GAIA-1—生成效果
Wayve LINGO-2模型
3.12 Waymo端到端
Waymo Foundation Model
“构建驾驶员”(Building the Driver)算法
“验证驾驶员”(Validating the Driver)算法
Waymo发布多模态端到端模型EMMA
EMMA解析(1)
EMMA解析(2)
EMMA解析(3)
EMMA模型的局限性
Waymo落地运营情况
3.13 极佳科技端到端
极佳科技公司简介
极佳科技世界模型演进路线
4D生成式世界模型分层搭建方式
世界模型的落地应用(一)
世界模型的落地应用(二)
极佳科技ReconDreamer
极佳科技世界模型DriveDreamer
极佳科技世界模型DriveDreamer 2
极佳科技DriveDreamer4D 的总体结构框
3.14 光轮智能端到端
光轮智能公司简介
端到端架构的数据需求
清华x光轮:自驾世界模型生成和理解事故场景
光轮智能核心技术
光轮智能“real2sim2real + realism validation”的核心技术栈
光轮智能数据标注和合成数据
3.15 鉴智机器人端到端
鉴智科技公司简介
全域端到端辅助驾驶方案
鉴智机器人端到端技术范式渐进一段式端到端方案详解
鉴智机器人端到端技术详解(1)
鉴智机器人端到端技术详解(2)
3.16 Nullmax端到端
Nullmax公司简介
MaxDrive辅助驾驶解决方案
新一代智能驾驶技术Nullmax Intelligence
Nullmax端到端技术架构
Nullmax端到端数据平台
HiP-AD
Nullmax量产情况
3.17 MobileEye端到端
Mobileye公司简介
Mobileye复合人工智能系统(CAIS)路线
Mobileye环绕式ADAS™方案
Mobileye SuperVision™/Chauffeur:高阶驾驶辅助系统
MobileEye量产情况
3.18 魔视智能端到端
魔视智能简介
魔视智能全栈式端到端智驾系统
魔视智能量产情况
04 主机厂端到端智能驾驶布局分析
4.1 小鹏汽车端到端智驾布局
小鹏端到端系统演进路线
小鹏世界基座模型
小鹏世界基座模型核心技术路径
小鹏云端模型工厂
世界基座模型研发的三个阶段性成果
小鹏端到端系统:架构
小鹏端到端系统(3)
小鹏端到端系统(4)
小鹏汽车的数据采集、标注和训练
4.2 理想汽车 端到端智驾布局
理想汽车端到端演进历程
从E2E+VLM双系统到MindVLA
理想MindVLA模型架构
理想MindVLA关键技术点一
理想MindVLA关键技术点二
理想MindVLA关键技术点三
理想MindVLA关键技术点四
理想汽车端到端方案(1):系统1的迭代演进
理想汽车端到端方案(2):系统1(端到端模型)+ 系统2(VLM)
理想端到端方案(3)
理想端到端方案(4)
理想端到端方案(5)
理想端到端方案(6)
理想技术布局:芯片
理想技术布局:数据闭环
4.3 特斯拉 端到端智驾布局
特斯拉2024 AI发布会解读
特斯拉AD算法发展历程
2023-2024特斯拉端到端进程梳理
特斯拉AD算法发展历程(1)
特斯拉AD算法发展历程(2)
特斯拉AD算法发展历程(3)
特斯拉AD算法发展历程(4)
特斯拉AD算法发展历程(5)
特斯拉AD算法发展历程(6)
Tesla:感知决策全栈一体化模型核心要素
特斯拉“端到端”算法
特斯拉世界模型(1)
特斯拉世界模型(2)
特斯拉数据引擎
Dojo超算中心介绍:总概览
Dojo超算中心介绍:特斯拉算力发展规划
4.4 零一汽车端到端智驾布局
零一汽车公司简介
零一汽车基于大模型的端到端智能驾驶系统
零一汽车端到端驾驶系统优势
零一汽车荣获端到端赛道国际挑战赛亚军
4.5 吉利&极氪端到端智驾布局
极氪一段式端到端大模型
极氪L3极智能驾驶技术架构
极氪千里浩瀚高阶智驾方案
吉利ADAS技术布局:吉利星睿智算中心(1)
吉利ADAS技术布局:吉利星睿智算中心(2)
吉利ADAS技术布局:吉利星睿智算中心(3)
星睿AI大模型
吉利智能驾驶大模型技术的应用
极氪汽车简介
极氪端到端系统:两段式方案
极氪正式发布端到端Plus
极氪端到端系统Plus解析
极氪端到端系统量产车型举例
4.6 小米汽车端到端智驾布局
小米汽车公司简介
小米汽车端到端VLA智能驾驶方案Orion
ORION框架解析
小米汽车物理世界建模架构
小米三层分别建模的多段式端到端
小米长视频生成框架
小米智能驾驶的下一个阶段就
小米道路大模型
小米新一代HAD
小米端到端技术路线明确
4.7 蔚来汽车 端到端智驾布局
蔚来重组智驾研发团队
蔚来从模型化到端到端
蔚来世界模型端到端系统
蔚来智能驾驶架构
蔚来端到端全研发阶段工具链
蔚来世界模型想象重建能力及群体智能
蔚来仿真器
蔚来软硬协同能力不断加强,迈向端到端系统时代
4.8 长安汽车 端到端智驾布局
北斗天枢2.0—天枢智驾
天枢智驾软件架构
长安集团品牌布局
长安ADAS战略:“北斗天枢”战略
长安端到端系统
端到端系统量产车型:
4.9 奔驰汽车 端到端智驾布局
奔驰和Momenta合作研发辅助驾驶系统
奔驰“纯视觉方案无图L2++全场景高阶智驾功能”
奔驰全新自研的MB.OS系统
4.10 奇瑞汽车端到端智驾布局
奇瑞大卓智能简介(1)
奇瑞大卓智能简介(2)
奇瑞智能驾驶五大技术布局
奇瑞端到端智能驾驶架构及优势
奇瑞端到端智能驾驶数字测评技术(1)
奇瑞端到端智能驾驶数字测评技术(2)
奇瑞猎鹰智驾端到端方案
猎鹰方案上车时间车型及未来规划
奇瑞汽车端到端系统发展规划
4.11 广汽端到端智驾布局
广汽星灵智行端到端具身推理模型架构
广汽星灵智行核心技术
广汽五大智驾产品平台
4.12 零跑端到端智驾布局
零跑汽车端到端高阶智驾
零跑汽车端到端高阶智驾应用场景
4.13 智己端到端智驾布局
上汽智己智驾系统迭代历程
智己与Momenta在智驾方面的合作
智己IM AD端到端2.0智驾大模型
智己IM AD端到端2.0智驾大模型核心技术
智己IM AD端到端2.0智驾大模型应用场景对比
4.14 红旗端到端智驾布局
红旗司南智驾技术架构
红旗端到端大模型核心技术
司南智驾方案
司南智驾方案上车时间车型及未来规划
4.15 其他车企的端到端进展